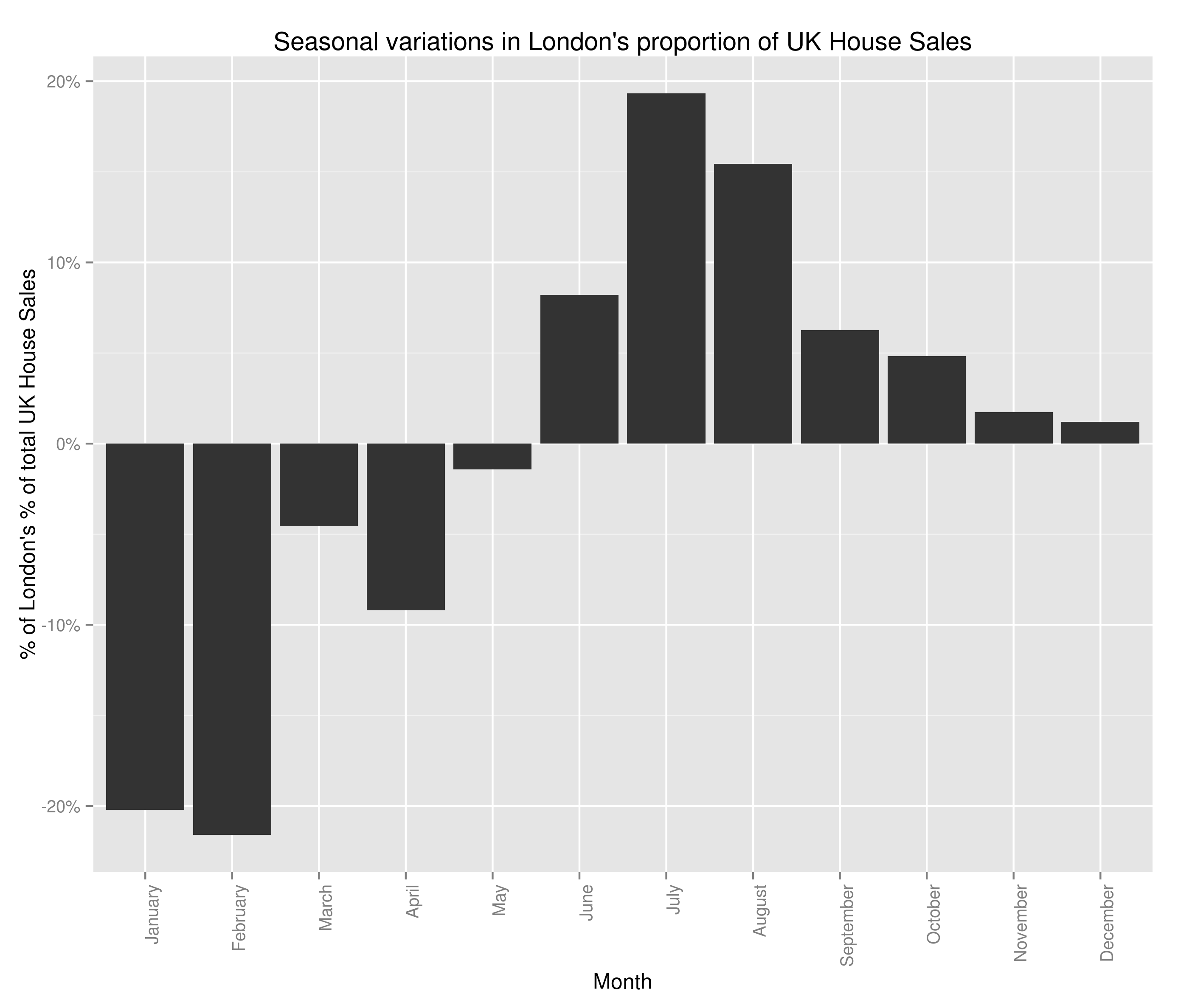
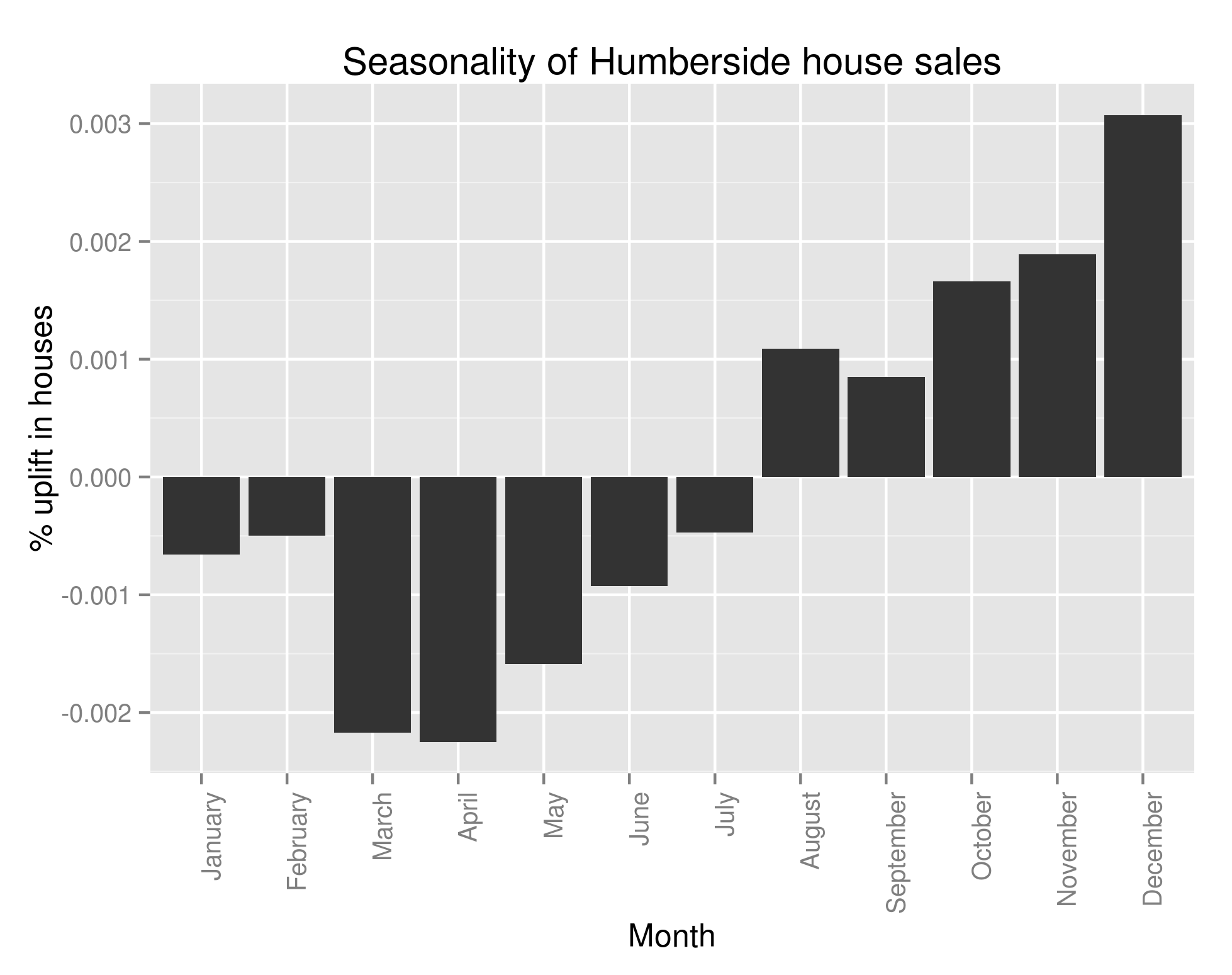
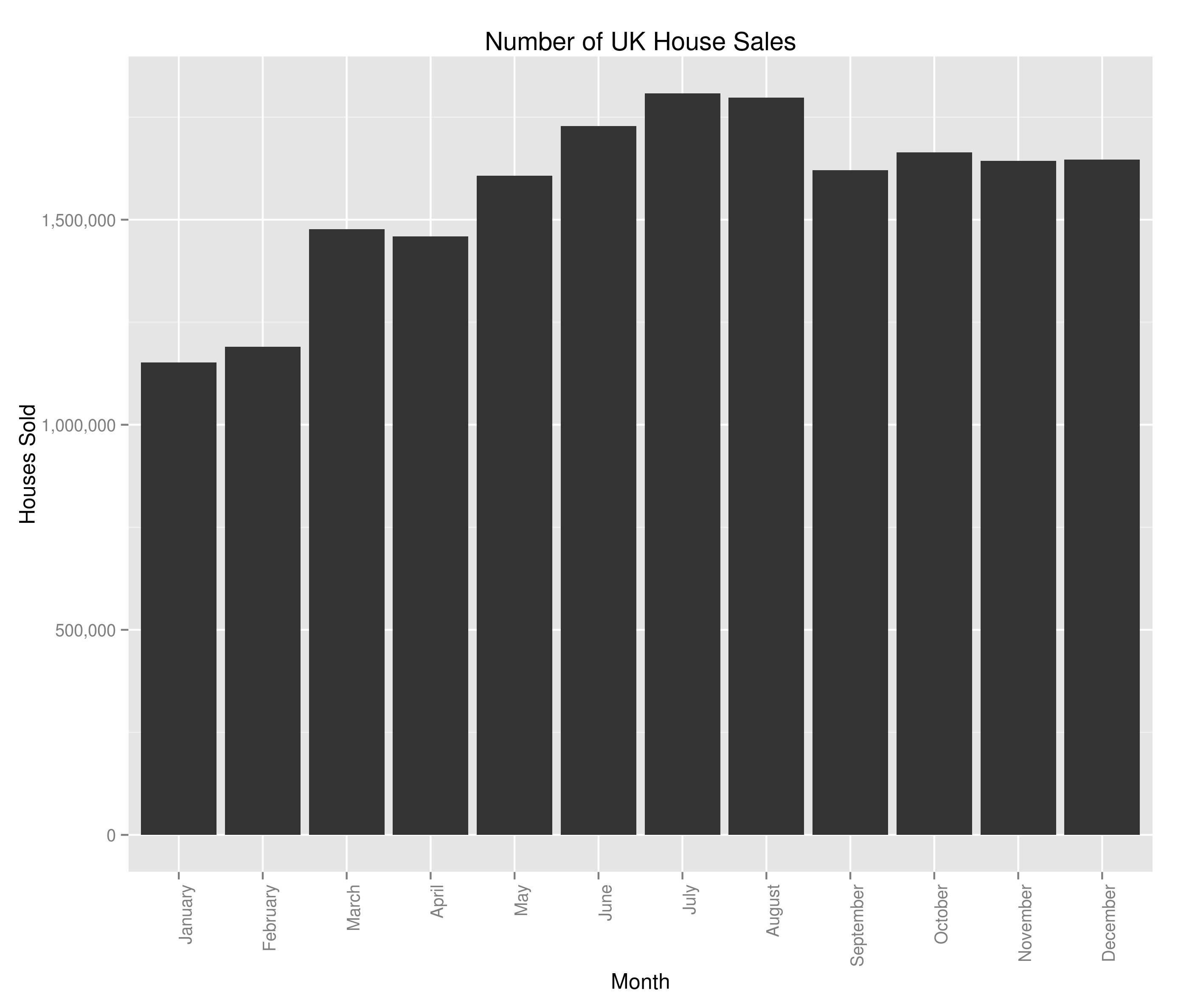
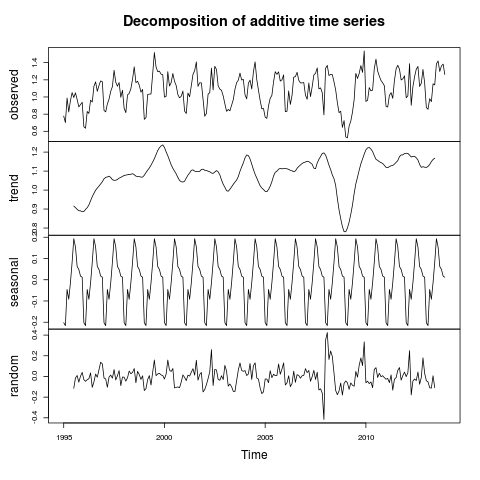
Hey all,
I’ve been tentatively threatening to write this post for a while now and I’ve been itching to do a bit of machine learning – I’m going to be walking through the steps required to run linear regression and an SVM on our housing sale data to try to predict future house sale prices. I’m not overly confident that it’s going to give us a huge deal of predictive power – any example I see online uses useful things like area of house or number of bedrooms. All I’ve got is when you sold it, where you sold it and the type of house (new or old, detached or terraced, freehold or leasehold) e.t.c. Not to worry – it’ll be a blast all the same.
First things first, which machine learning technique should we use? We’ll be using a supervised algorithm as we have a labelled training set (we can tell our classifier what the right answer is). We’re looking at a regression problem, not a classification problem (we’ve trying to predict a continuous variable, not a discrete one). All in all, that’s screaming linear regression to me. As an additional bonus though, I also happen to know that SVMs work very well for this kind of problem and have used Libsvm for similar things in the past.
In terms of the bits of kit I’ll be using – let’s start off, as I always seem to, in bash.
cut -d ',' -f3- pp-all.csv | cut -d ',' -f1-13 | tr -d '"' > pp_all_for_weka.txt
Just a bit of formatting but, if you’ve followed the posts through then you’ll have pp-all.csv on your computer. If you’ve not see here for how to get it.
Now we’re here, you may notice the strange filename – Weka is a machine learning library for Java. We’ve been using it a bit at work recently and I fancied getting a bit more experience of it. I’ll be using Weka for the linear regression; I’ve not got the heart to do a Weka installation post just yet (it’s not difficult, I’m just tired) but will do one if there’s any demand. I’m going to be using LibSVM for my support vector machine calculations and again, not going to talk you through the install unless you fancy it. The reason I’ve told you about that is because I’m now going to convert my CSV file into an ARFF file and a libsvm formatted file. While I’m at it, I’m going to convert all of my values (postcodes, dates e.t.c.) into numbers. Doing this allows me to very easily feed this data set into the above programs and get an answer out relatively easily.
Could we write the algorithms ourselves? Sure – but not nearly as well as they’ve already been written. Sidebar: if you’re interested in understanding how all these algorithms work I’d encourage you to check out Andrew Ng’s lecture series on Coursera. It’s excellent.
Anyway, to run the conversion and to output the two different files I wrote the following Python script:
#!/usr/bin/python
class mapping_dictionary(object):
def __init__(self, output_file, svm_file):
self.mapping = {}
self.mapping_count = {}
self.column_names = ['date', 'postcode', 'f_map', 'n_map', 'l_map', 'addy', 'addy1', 'addy2', 'addy3', 'addy4', 'addy5', 'addy6', 'price']
self.writer_file = open(output_file, 'w')
self.svm_file = open(svm_file, 'w')
def shut_file(self):
self.writer_file.close()
self.svm_file.close()
def add_to_dictionary(self, column, key):
if column not in self.mapping:
self.mapping[column] = {}
self.mapping_count[column] = 0
if key not in self.mapping[column]:
self.mapping[column][key] = self.mapping_count[column]
self.mapping_count[column] += 1
def interpret_list(self, listy):
if len(listy) != len(self.column_names):
print "Error - unexpected number of columns in the line: %d" % len(listy)
return None
for index, value in enumerate(listy):
if index == 12:
try:
value = int(value.strip().strip('n'))
except:
break
self.add_to_dictionary(self.column_names[index], value)
self.write_to_file(listy)
self.write_libsvm_file(listy)
def write_to_file(self, listy):
string_to_write = ','.join([str(self.mapping[self.column_names[index]][entry]) for index, entry in enumerate(listy) if index != 12])
string_to_write += ",%sn" % str(listy[-1])
self.writer_file.write(string_to_write)
def write_libsvm_file(self, listy):
string_to_write = ' '.join([str(index + 1) + ":" + str(self.mapping[self.column_names[index]][entry]) for index, entry in enumerate(listy) if index != 12])
string_to_write = str(listy[-1]) + " " + string_to_write + "n"
self.svm_file.write(string_to_write)
mapping = mapping_dictionary('nice_weka_output.txt', 'nice_libsvm_output.txt')
with open('pp_for_weka.txt', 'rb') as f:
while True:
line = f.next()
mapping.interpret_list(line.strip().strip('n').split(','))
mapping.shut_file()
A reasonable amount of Python happening there – if you were worrying about it, I really wouldn’t. All we’re doing is replacing every field (apart from price) with an integer and outputting that in two different formats as we work our way through the file. If I was being thorough I’d remove the hardcoded list at the top, require a header row, take the filenames as command line arguments and then it’d work as a general tool for formatting CSVs as libsvm and arff files. Actually, that doesn’t sound like a bad idea at all.
Now you’ve got your input files, it’s child’s play to run our algorithms to create models that we can pass new data to. I’ll create a separate post detailing the output of the above two classifiers but it looks like I’ll have to leave them running through the night!
Until then.