Having spent over six months working as part of a small team to design and build a new search engine for one of Europe’s largest online retailers, I found myself learning a lot about the inner workings of modern search engines. It was my first real exposure to search – a technology which is really central to everyone’s online experiences.
Search is more complex than it may seem at first. An e-commerce search engine is built to enable customers to find the products that they are looking for. A customer will search for a product, perhaps by name, and the search engine will check the database of products and return those that match the search query. Perhaps you could write a search engine with a simple SQL query:
SELECT * FROM products WHERE product_title LIKE '%{search_query}%'
This may seem to yield decent results for some search queries – but there are many problems with such an approach.
- Exact substring matches only. A search for ‘matrix dvd’ won’t match ‘The Matrix (1999) – DVD’.
- No way to order the results. What if the query is ‘xbox’ and 100 products have ‘xbox’ in their title? Xbox games, xbox accessories and xbox’s themselves. Our query will find these products, but we have no way to order our results based on the most relevant matches.
- Only searching a single field. What if we want to enable our customers to search for authors, directors, brands etc? Sure, we could change our query to look in multiple fields, but surely those fields shouldn’t be given the same importance as the product title, right?
- No support for synonyms. A search for ‘football’ won’t match any products with ‘soccer’ in their title.
- No stop word filtering. These are common words like ‘and’, ‘the’ and ‘of’. These words are usually not important in a search, especially in determining which products match a query. When we are searching just on product title, the negative effect of stop words is not so noticeable. But imagine if we want to extend our search engine to search over a larger body of text, such as a product description. In this case, most of the products in our database will contain stop words in the description, and it certainly doesn’t mean they should match the query.
- No stemming. This is the process of truncating a word to its simplest form, in order to extract its root meaning. For example, ‘fisher’, ‘fishing’ and ‘fished’ all have similar meanings. These words could all be stemmed to ‘fish’, so that a search for any one of these terms will match all products related to fish.
- Term frequencies are not considered. The frequency of a term in the corpus (i.e. across the entire database of products) can actually give us a lot of information about how important each term in a query is. If you consider a search for ‘game of thrones’. There are three terms in this query, one of which is a stop word. Now imagine that we are a game retailer and all of our products are games. Many of the products in our database will match the term ‘game’ while only a few will match the term ‘thrones’. This is because the term frequency for ‘game’ across our entire database is a lot higher than it is for ‘thrones’. With this knowledge, we know that ‘thrones’ is the more important term – products which match this word are more relevant.
- Typical SQL databases won’t scale. As our product base and the volume of queries per second grows, standard databases will quickly become slow – partly because they are not designed for full-text search, where we are searching bodies of text for partial matches.
All of these problems can be solved with ideas which have been developed in the field of information retrieval. There are two key concepts which give modern day search engines their speed and quality:
- Indexing – An index is a data structure which enables us to perform blazingly fast searches within our database for documents which match a query (in the e-commerce case, a document corresponds to some information describing a product). Without an index, we would have to look in every document and compare every term with our query – a slow and inefficient process. Every document that we want to be able to search over is indexed. To index a document, every field of the document is broken down into a set of tokens and these tokens are added to the index. This process is called tokenization. The way tokens are extracted will vary depending on what we want to achieve, but tokens are often stemmed words, with stop words omitted. Using our earlier example, if a document contains the word ‘fishing’, then perhaps the (stemmed) token ‘fish’ would be added to our index.
- Relevance Scoring – When executing a search query, the first step is to find all documents which match the query using our index. However, having found these documents, a search engine needs to give each document a score based on how well it matches the query – so that the most relevant results appear first in your search results. There are multiple ways to do relevancy scoring, but one of the most common ways is known as TF/IDF (term frequency – inverse document frequency). The idea is that, if a term from the query appears more times in a document, then that document should receive a higher score. But, if that term appears many times in our corpus (i.e. it is a more common term), then the document should receive a lower score. Combining these two ideas, we can do some linear algebra to find the most similar documents to our query. For a detailed explanation of this, check out this article.
In the diagram below I have tried my best to depict the processes of indexing (at index time) and document retrieval (at query time).
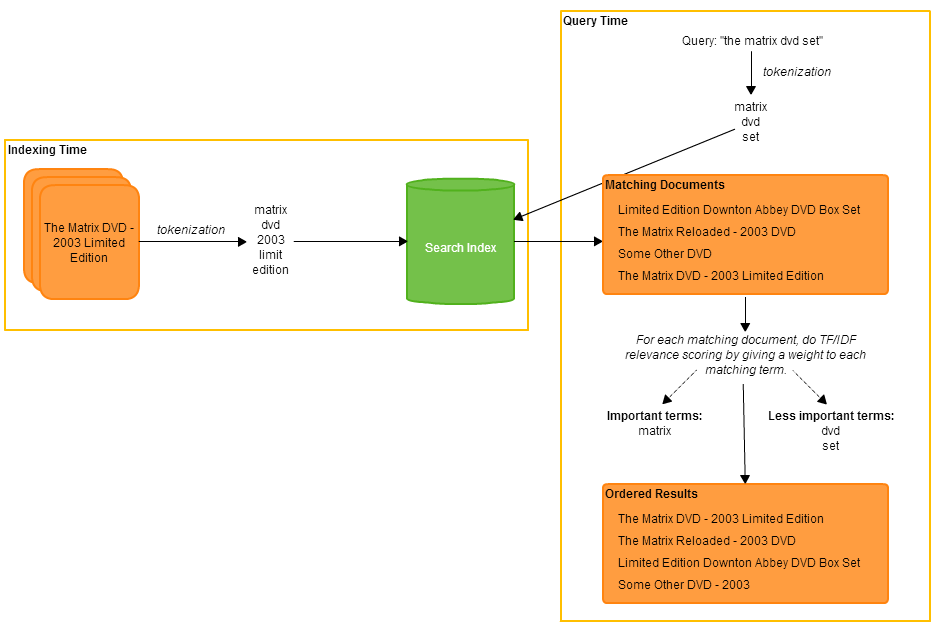
The processes of indexing and retrieval in a typical search engine
Today, two of the most widely used general purpose search frameworks are Apache Solr and Elasticsearch. Both are distributed search engines written on top of Apache Lucene, a high performance full-text search library which provides implementations of the above concepts. Solr is extremely mature and has long been the industry standard, but in the last few years Elasticsearch has received a lot of attention for a number of reasons: it is based on more modern principles, it is designed to deal with very large amounts of data and without the legacy constraints of Solr, the development community were able to make very rapid progress. In our case, (with our desire to always use the latest technologies) we decided to go with Elasticsearch.
In my next post, I will discuss some ideas, best practices and lessons learned from using Elasticsearch to build a search engine for e-commerce.