Hey all,
Standard apologies about not posting for ages and all that. However, assuming you don’t care – let’s get onto the business of things. Firstly – this is a plot of the document similarities between all of the Tory/Labour manifestos from 1979 to 2017:
Document Similarity
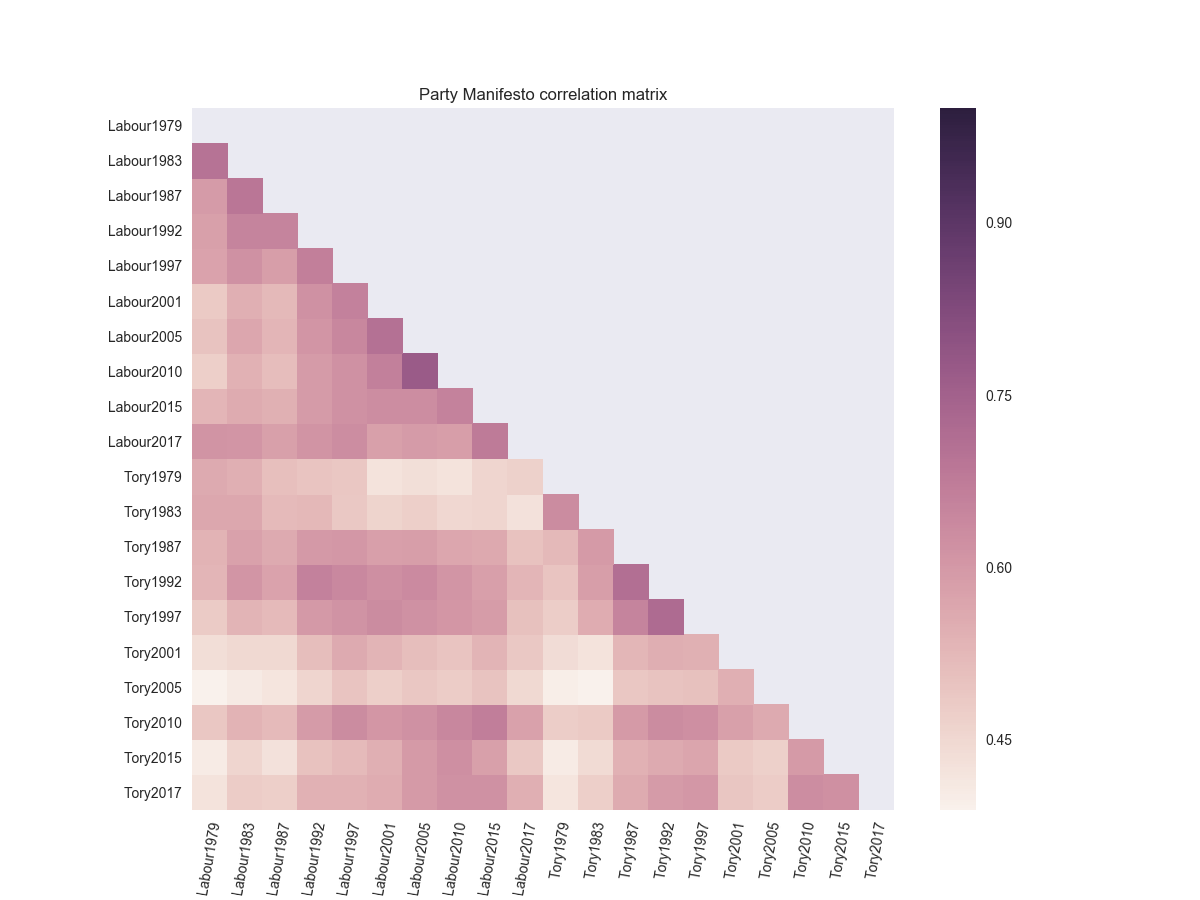
Party manifesto cosine similarity
Is that interesting? Maybe. In general, a party’s manifesto is most similar to the same party’s manifesto of the previous election. The most similar manifestos are Labour’s of 2005 and 2010, closely followed by the Tory’s 1992 and 1997 efforts (if it works, it turns out you might still need to fix it!)
Most interestingly for me is the Tory shift in 2010 – the manifestos it was most similar to is Labour starting at 1997 and going all the way through to 2015. If you think that David Cameron and Tony Blair were political bedfellows then the manifestos might not disagree with that view.
So what about in 2017? Labour’s manifesto has managed something that no other manifesto has managed – it’s more similar to every other Labour manifesto than it is to any Tory manifesto. In contrast, Theresa May’s effort leans on Labour’s recent history as well as David Cameron’s time in charge of the Conservatives.
Similar Words
When we say a document is similar to another document, is there a way for us to see what that means and how it works? Well let’s look (for chosen pairs of manifestos) which words are shared. I’m interested in which words are most important to two documents but which aren’t important (or don’t feature) in any of the other documents. Based on that intuition, let’s look at some examples…
Labour 2017 – Tory 2017
– Brexit
– leave European Union
– protections
– devolved administrations
Labour 1983 – Labour 2017
– workers rights
– education service
– publicly owned
Labour 1997 – Tory 2010
– low carbon
– change society
– welfaretowork
I think that’s pretty cool! So we can see which themes are shared across manifestos! Could we build a predictive model to work out what makes a winning manifesto? Absolutely! Would it likely lead to massive overfitting and be practically useless? I’d have thought so.
Details
For those interested in exactly how I did the above, see this repo: repo
As a general summary:
1.) Clean the manifesto text and remove any ‘words’ that are just numbers.
2.) Remove English stopwords and generate 3-grams (“I went to”, “went to the”, “to the shop”).
3.) Perform TF-IDF (work out which words are most important in a document, and across all documents).
4.) Calculate cosine similarity to work out how similar each document is to each other document
—-
For the common words I’ve done something a bit different and written my own algorithm (because I couldn’t find one that did what I wanted it to). If you know of a better way of doing this (finding terms for maximising similarity between documents while minimising for all other documents) let me know!
1.) For each combination of manifesto pairs, generate a column vector with a 1 when the entry corresponds to one of the manifesto pairs and a -1 when the entry doesn’t.
e.g. (1,1,-1,-1,-1…) would be the vector for (Labour1979, Labour1983) (1,-1,-1,-1,1,-1,…) would be the vector for (Labour1979,Labour1997).
2.) Stick all of those columns together to form a matrix (A).
3.) Multiply the transpose of the TFIDF matrix (B) with the combinations matrix (A).
4.) Each column in the resultant matrix (C) now has a score for every single word present across all of the corpuses. The highest scoring words will be ones that have a large TF-IDF score in the two documents we’re interested in, but a small TF-IDF score in all the other documents.
5.) As such, pick to the top N for each column in the resultant matrix (C) and map them back to the feature names that generated the TFIDF matrix (A) in the first place.
Sorry if that explanation isn’t especially clear – have a look at the code and let me know if there’s a better way of doing things!
Choose love, Manchester.