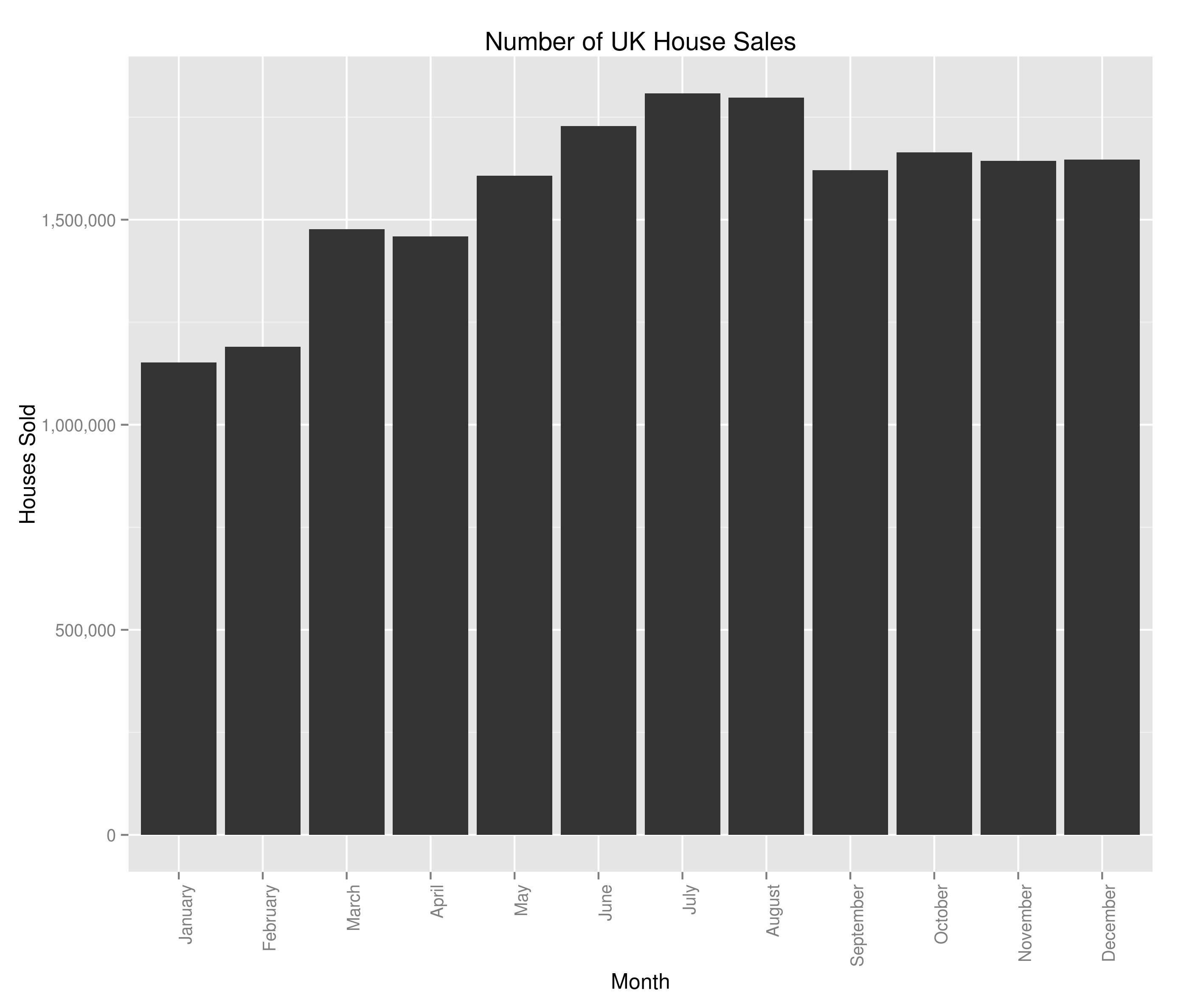
Hi all,
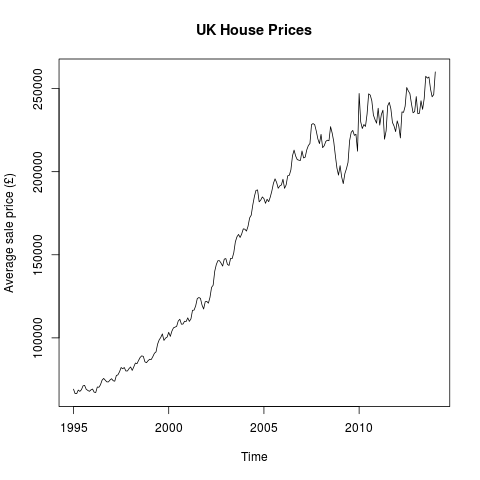
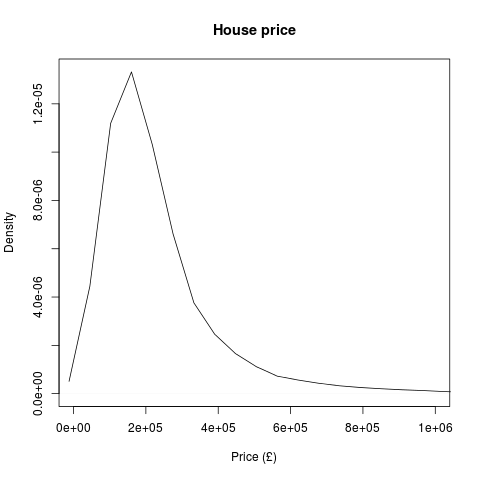
If you’ve been following all of these blog posts then you’re in a minority of one. However, you’ll also know that we’ve taken all of the UK house sales in the last 18 years or so and have found a bunch of things out. We’ve seen the spread of average house price by region, we’ve seen seasonality in the average house price, we’ve seen the impact the housing crash had on average house price (not that much) and on number of houses sold (an awful lot). Finally, we investigated seasonality of number of house sales by region and in doing so, found that London suffered the housing crash worse than other areas but almost immediately picked itself up and is in fact (relative to the rest of the country) better off than it was before the crash.
I had a couple of ideas for investigations in my last post – one of which was finding the most sold house in the UK and seeing if there was a correlation between the times a house has sold and its price. I’ll briefly tackle this because it’s one line of bash – working with our file pp-all.csv (all of our data in one big text file) the following command will give us the top 100 most sold properties in the UK in the last 18 years:
cut -d ',' -f5,9-15 pp-all.csv | tr -d '"' | tr ',' ' ' | sort | uniq -c | sort -k1 -n -r | head -n 100
The top 10 are as follows (with the format: # of sales | postcode | address ) :
24 L17 3BP 48 FLAT 5-19 ULLET ROAD LIVERPOOL LIVERPOOL MERSEYSIDE
19 W8 6JE 126 FLAT 1-10 LEXHAM GARDENS LONDON KENSINGTON AND CHELSEA GREATER LONDON
19 LS2 7LY 31 EASTGATE LEEDS LEEDS LEEDS WEST YORKSHIRE
16 SE1 3FF 41 FLAT 67 MALTBY STREET LONDON SOUTHWARK GREATER LONDON
16 PL2 1RR 48 HADDINGTON ROAD PLYMOUTH CITY OF PLYMOUTH CITY OF PLYMOUTH
16 BN43 5AR SHOREHAM COURT 3-10 THE CLOSE SHOREHAM-BY-SEA ADUR WEST SUSSEX
15 IP1 3PW 54 ANGLESEA ROAD IPSWICH IPSWICH IPSWICH SUFFOLK
14 WA16 6JD TATTON LODGE 1-6 MOORSIDE KNUTSFORD CHESHIRE EAST CHESHIRE EAST
14 M3 6DE FRESH 138 APARTMENT 1008 CHAPEL STREET SALFORD SALFORD SALFORD
14 M19 2HF 35 CENTRAL AVENUE MANCHESTER MANCHESTER GREATER MANCHESTER
I decided against pursuing this investigation as a quick hunt on Zoopla tells me that flats 5-19 Ullet Road were sold individually and so we’re just seeing the results of grouping and nothing overly interesting. I guess there are certain houses in there of interest – why has 48 Haddington Road been sold 16 times since 1995?
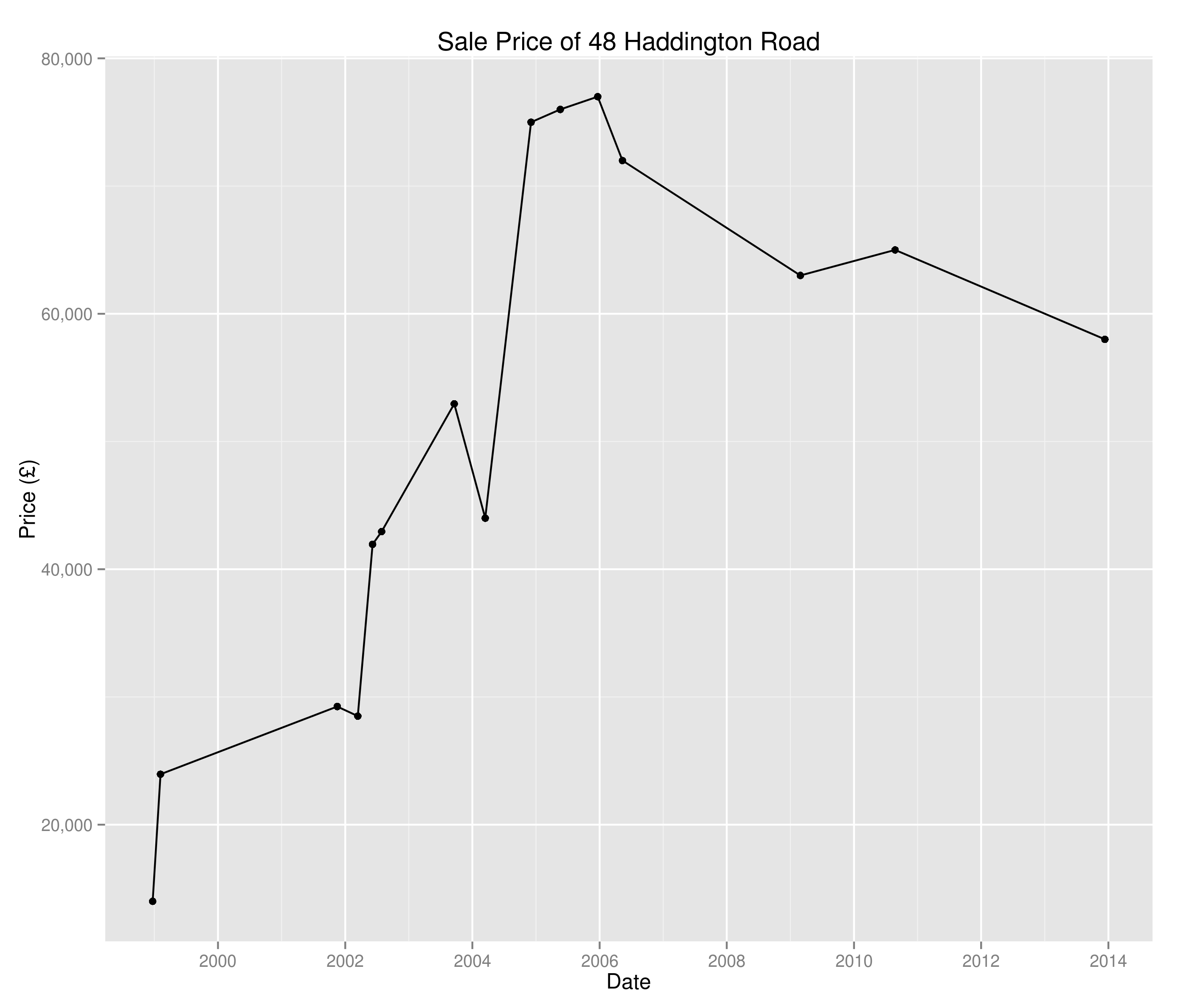
Sale prices of 48 Haddington Road since 1995
I don’t really know and I’m not going to investigate – I think I’d rather look at the age old question:
“When should estate agents take holidays?”
Of course, this is every bit as much a question of where national estate agents should have their staff distributed throughout the year, which region removal companies should target throughout the year, where travelling housing surveyors are most likely to pick up business e.t.c.
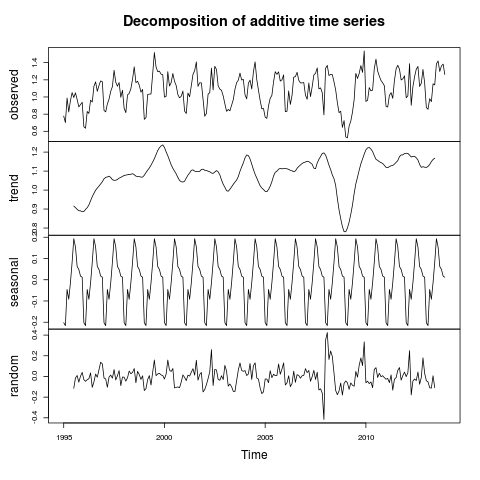
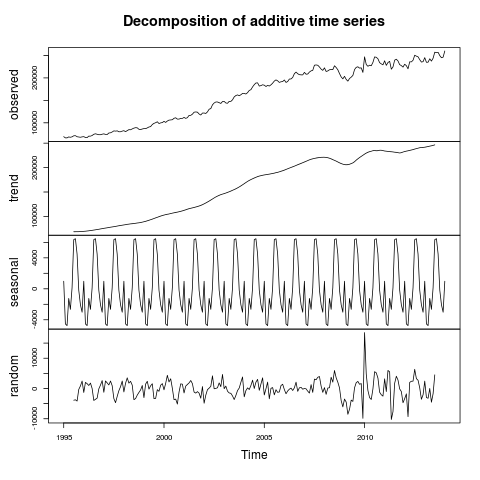
In the last post we were able to create time series of the percentage of UK house sales a region was responsible for. Now we’re going to create a whole bunch of time series (one for each region) and perform clustering on them to see when each region peaks and troughs. Note we’re looking at a percentage of total sales here and not absolute numbers – I’m also not looking at the saturation of the market or anything like that.
I’m going to use Markov Clustering in this example – don’t worry too much about this (if you don’t want to), I’ll do a post on Markov Clustering at a later point. For now, all you need to know is that it’ll cluster our data in a sensible way.
So, down to business:
## Get the data I need in a small(er) table
library(reshape2)
library(rEMM)
mini_frame <- data.frame(newFrame$Datey, newFrame$Region, newFrame$Percent)
colnames(mini_frame) <- c("Datey", "Region", "Percent")
ts_frame <- dcast(mini_frame, Datey ~ Region, sum)
## Have found I need to initialize this before I kick off
seasonal_ts_frame <- data.frame(matrix(0, nrow=12, ncol=length(colnames(ts_frame)))
colnames(seasonal_ts_frame) <- colnames(ts_frame)
row.names(seasonal_ts_frame) <- factor(month.name, levels=month.name)
for (i in 1:ncol(ts_frame)) {
decomposed_ts <- decompose(ts(ts_frame[,i], frequency=12, start=c(1995,1)))$seasonal[c(1:12)]
seasonal_ts_frame[[colnames(ts_frame)[i]]] <- decomposed_ts
}
cor(seasonal_ts_frame)
emm <- EMM(threshold=0.2, measure="eJaccard")
build(emm, cor(seasonal_ts_frame))
cluster_centres <- data.frame(cluster_centers(emm))
cluster_frame <- data.frame(lapply(cluster_centres, which.max))
row.names(cluster_frame) <- c("Cluster")
cluster_frame <- data.frame(t(cluster_frame))
colnames(cluster_frame) <- c("Region", "Cluster")
cluster_one <- subset(cluster_frame, Cluster==1)
cluster_two <- subset(cluster_frame, Cluster==2)
## A list of all the cluster one regions
seasonal_ts_frame[,(names(seasonal_ts_frame) %in% row.names(cluster_one))]
## Now the biggie - let's see the points on a map
library(maps)
library(mapdata)
library(RCurl)
library(RJSONIO)
## A couple of functions allowing us to dynamically get the longitude and latitude of regions
construct.geocode.url <- function(address, return.call = "json", sensor = "false") {
root <- "http://maps.google.com/maps/api/geocode/"
u <- paste(root, return.call, "?address=", address, "&sensor=", sensor, sep = "")
return(URLencode(u))
}
gGeoCode <- function(address,verbose=FALSE) {
if(verbose) cat(address,"n")
u <- construct.geocode.url(address)
doc <- getURL(u)
x <- fromJSON(doc,simplify = FALSE)
if(x$status=="OK") {
lat <- x$results[[1]]$geometry$location$lat
lng <- x$results[[1]]$geometry$location$lng
return(c(lat, lng))
} else {
return(c(NA,NA))
}
}
## Plot a UK map
map('worldHires', c('UK', 'Ireland', 'Isle of Man','Isle of Wight'), xlim=c(-8,2), ylim=c(51.8,54.2))
longitude_and_latitude <- data.frame(sapply(paste(row.names(cluster_one), ", UK", sep=''), function(x) gGeoCode(x)))
row.names(longitude_and_latitude) <- c("Latitude", "Longitude")
longitude_and_latitude <- data.frame(t(longitude_and_latitude))
points(longitude_and_latitude$Longitude, longitude_and_latitude$Latitude, col=1, pch=4)
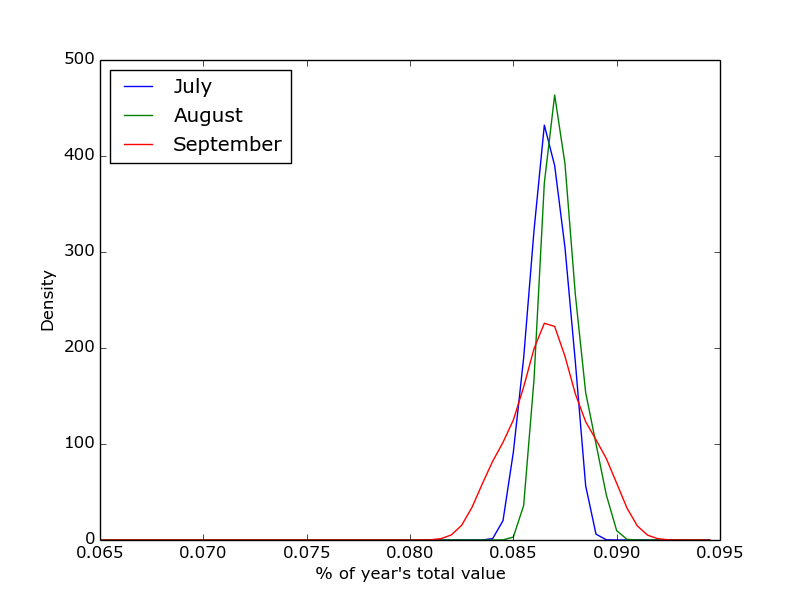
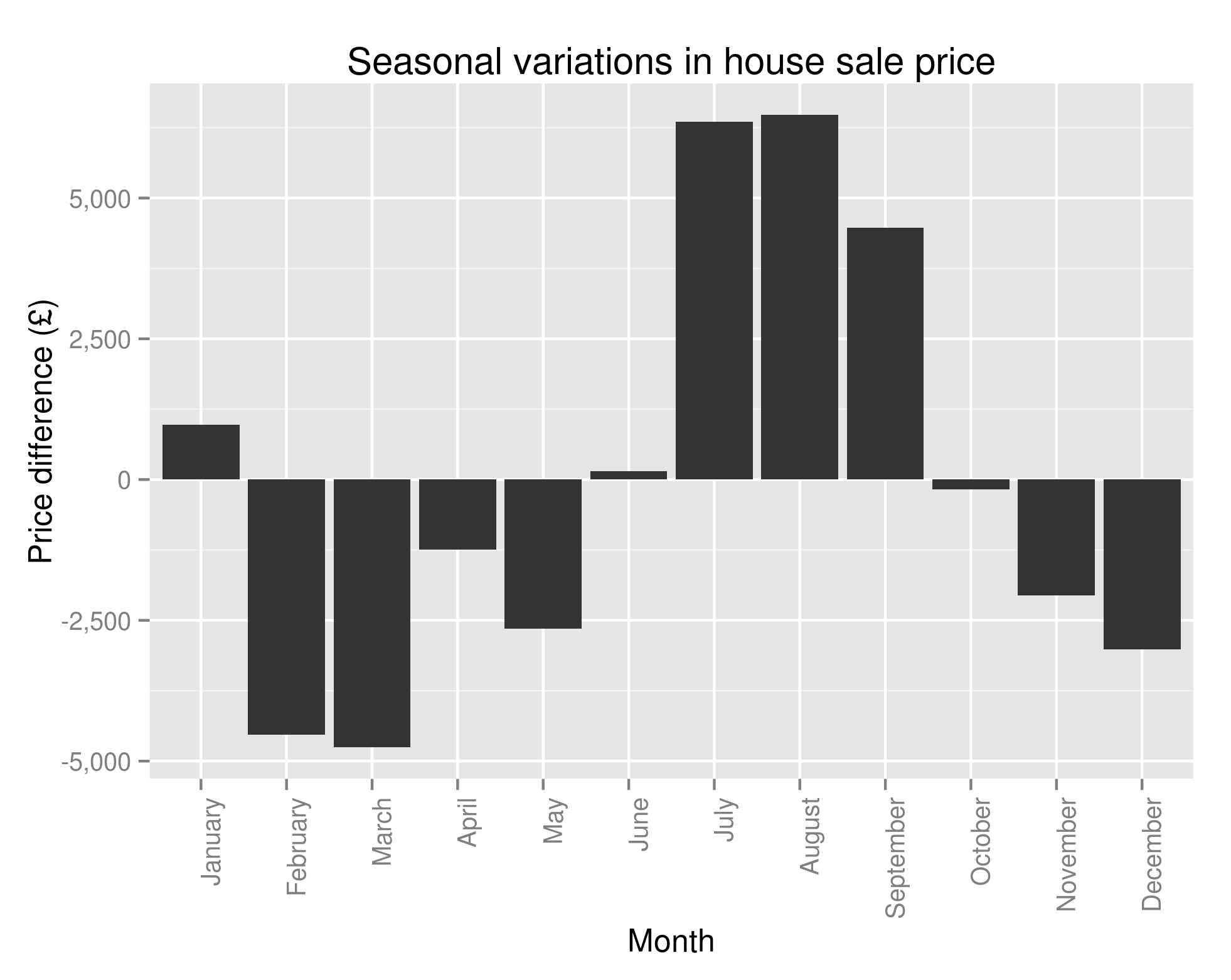
O.K, so there’s an awful lot of R code in there and all to produce a slightly underwhelming graph. Where does the great divide come in seasonality of house sales? Why, in South Wales and North East England of course:
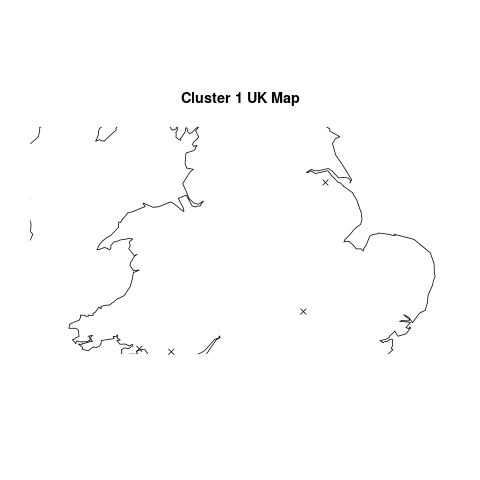
Regions that break the national housing seasonality pattern
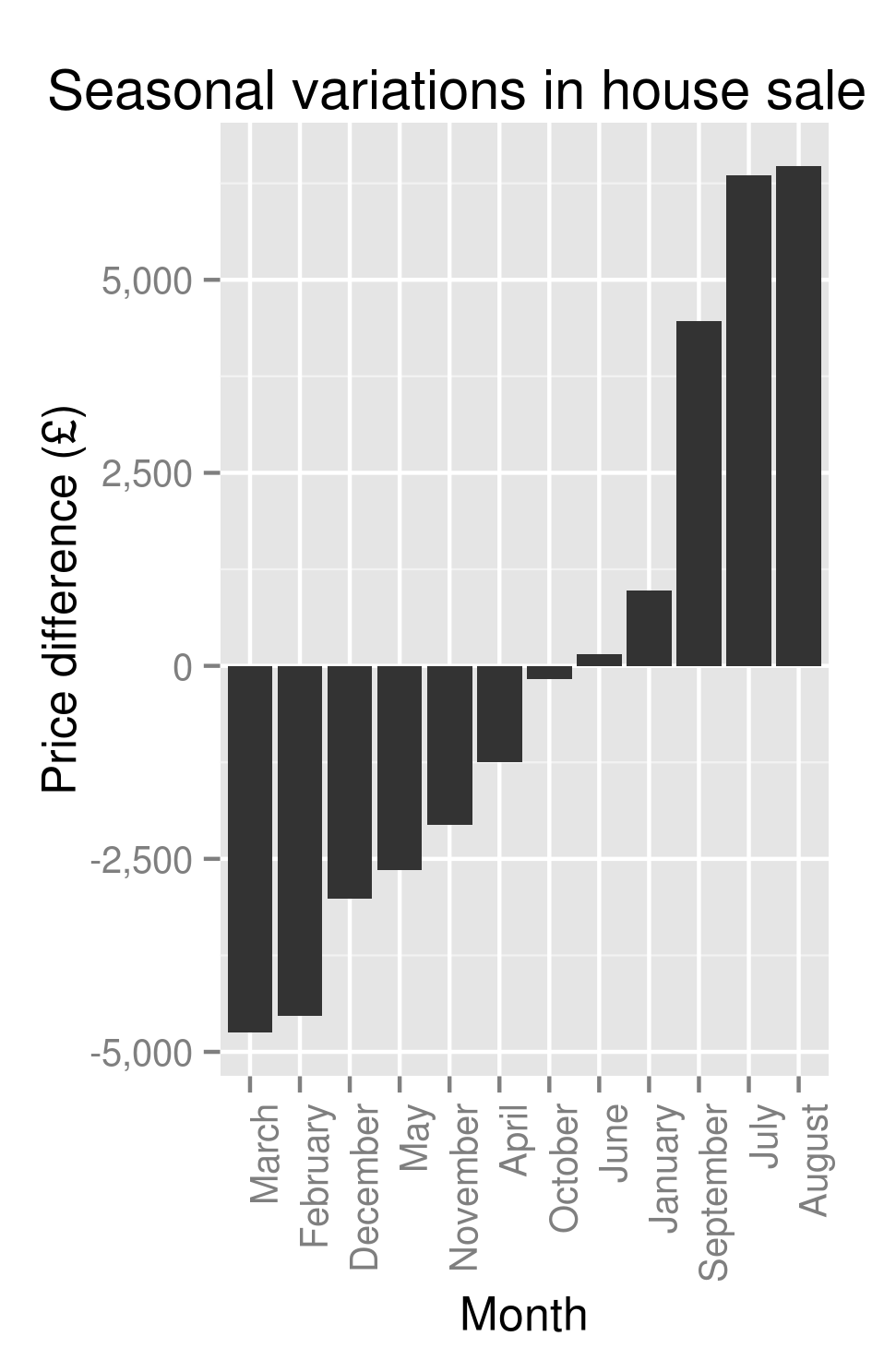
Semi-ignoring our ability to get accurate latitude and longitude using what was at best, a wildly optimistic attempt at doing so, we have some fairly believable (if confusing clusters). The bulk of the country follows the trend set by London:
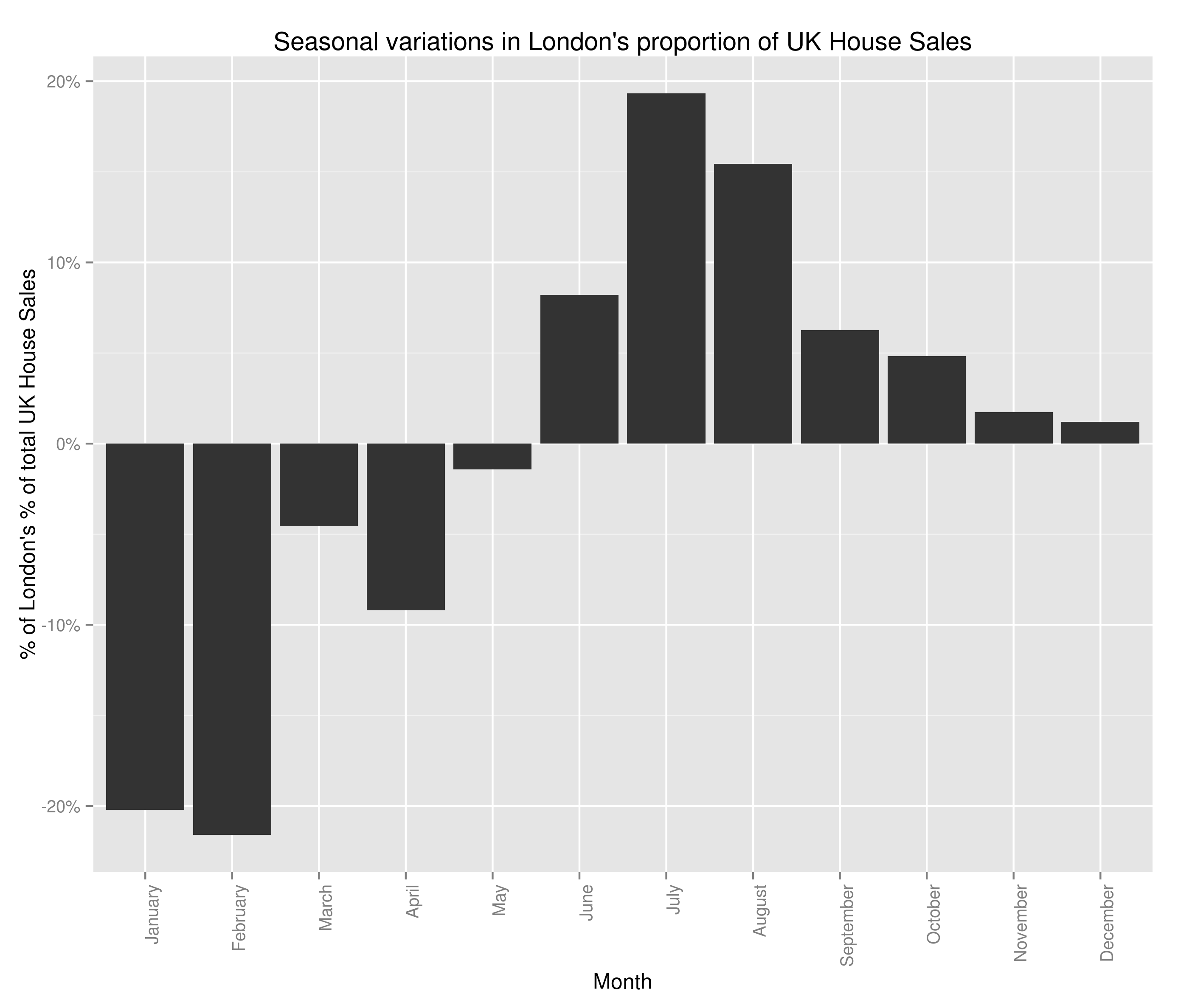
Seasonal Variations in London’s Percent of the UK Housing Market (by number sold)
with lots of houses being bought in the summer and many fewer being bought in the winter. However, 6 regions in South Wales (including all of Glamorgan), 2 regions in the North East of England and Avon all follow this trend:
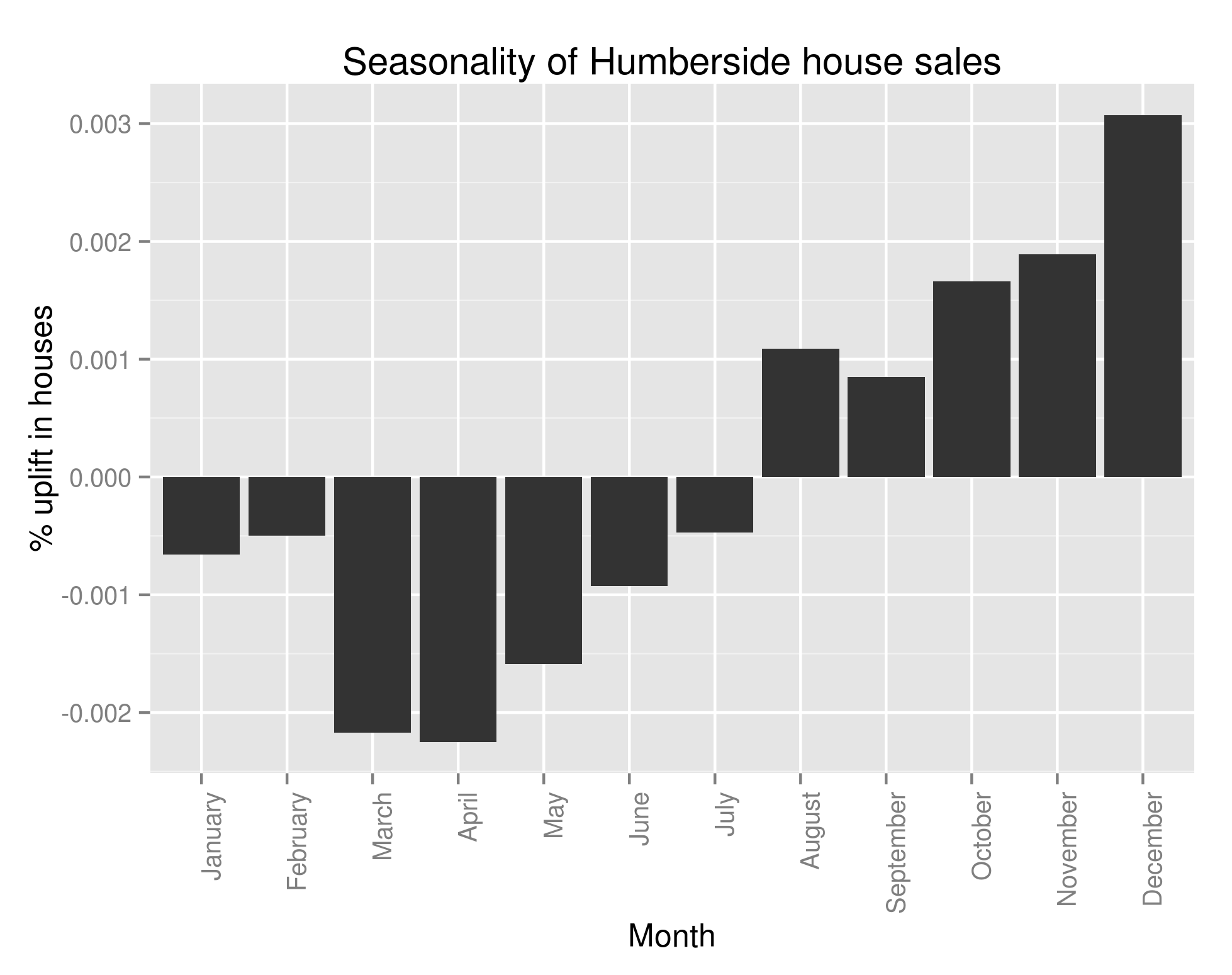
Seasonal Variations in Humberside’s Percent of the UK Housing Market (by number sold)
This struck me as very strange indeed and so I looked at the original data and what should I discover? That almost all of the above analysis is wrong. If only we’d have performed the following query the folly of all that I’ve done would have become clear:
colSums(ts_frame==0) > 200
Every single one of the regions that didn’t follow our pattern had substantial missing data. One with more knowledge of British geography may have been able to spot that those counties had ceased to exist in 1995/6. The reason why I’ve left all that analysis in, aside from the fact that there are a few useful bits of code in there (plotting the regions on a UK map may well be helpful to somebody), is to show that it’s really really important to check your data when you’ve got an unexpected result. It’s also important to check it whatever the result, but in data analysis, if something seems dodgy there’s a good chance it is.
When I strip out all regions with missing data, we in fact see that all of the regions follows the same pattern as Greater London. Bugger.
Going to draw this one to a close – what have we discovered? Well, we now know that every single region in the UK follows the same seasonality pattern when it comes to house sales: lots more in summer than winter. We also know that the average house price follows the same trend. I’ve not shown that the regionality isn’t a factor in the increasing average house price (you could imagine the scenario where the more expensive areas see a greater surge in house sales in the summer than the less expensive areas). I’m not sure what I’m going to work on next – I’m getting a bit sick of house prices.
It’ll likely either be:
1.) Regional variations in average house price.
2.) Which regions see the greatest increase in number of house sales in summer – clustering as before.
3.) Seasonality of any other variable (type of house, new versus old, freehold versus leasehold)
4.) Build a predictive model to calculate something specific (number of old detached houses sold in Derbyshire every month for the next year).
5.) Identify towns with the fastest growing (and falling) average house price over the last x years. Try to use this to predict which areas will see similar areas of growth/decline in the future.
6.) Finding correlated stock opening/closing prices over historical data and using this to make £££££. Obviously that one is a bit different but does involve ££££.