Hi all,
Bit of a different blog coming up – in a previous post I used Markov Clustering and said I’d write a follow-up post on what it was and why you might want to use it. Well, here I am. And here you are. So let’s begin:
In the simplest explanation, imagine an island. The island is connected to a whole bunch of other islands by bridges. The bridges are made out of bricks. Nothing nasty so far – apart from the leader of all the islands. They’re a ‘man versus superman’, ‘survival of the fittest’ sort and so one day the issue a proclamation. “Every day a brick will be taken from every bridge connected to your island and the bricks will be reapportioned on your island back to the bridges, in proportion to the remaining number of bricks in the bridge.”
At first, nobody is especially worried – each day, a brick disappears and then reappears on a different bridge on the island. Some of the islands notice some bridges getting three or four bricks back each day. Some hardly ever seem to see a brick added back to their bridge. Can you see where this will lead in 1000 years? In time, some of the bridges (the smallest ones to start off with) fall apart and end up with no bricks at all. If this is the only way between two islands, these islands become cut off entirely from each other.
This is basically Markov clustering.
For a more mathematical explanation:
Let’s start with a (transition) matrix:
import numpy as np
transition_matrix = np.matrix([[0,0.97,0.5],[0.2,0,0.5],[0.8,0.03,0]])

In the above ‘islands’ picture those numbers represent the number of bricks in the bridges between islands A, B and C. In the random-walk interpretation, those are the probabilities that you’ll end up at each node as the number of random walks tends to infinity. In my previous post on house prices, I used a correlation matrix.
First things first – I’m going to stick a one in each of the identity areas. If you’re interested in why that is, have a read around self-loops and, even better, try this out both with and without self-loops. It sort of fits in nicely with the above islands picture but that’s more of a fluke than anything else – there’s always the strongest bridge possible between an island and itself. The land. Anyway…
np.fill_diagonal(transition_matrix, 1)

Now let’s normalize – make sure each column sums to 1:
transition_matrix = transition_matrix/np.sum(transition_matrix, axis=0)

Now we perform an expansion step – that is, we raise the matrix to a power (I’ll use two – you can change this parameter – in the ‘random-walk’ picture this can be thought of as varying how far a person can walk from their original island).
transition_matrix = np.linalg.matrix_power(transition_matrix, 2)

Then we perform the inflation step – This involves multiplying each element in the matrix by itself (to a power) and then normalizing on column again. Again, I’ll be using two as a power – increasing this leads to a greater number of smaller clusters:
for entry in np.nditer(transition_matrix, op_flags=['readwrite']):
entry[...] = entry ** 2

Finally (for this iteration) – we’ll normalize by row.
transition_matrix = transition_matrix/np.sum(transition_matrix, axis=0)

And it’s basically that simple. Now all we need to do is rinse and repeat the expansion, inflation and normalization until we hit a stable(ish) solution i.e.
for some small epsilon.
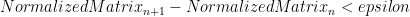
Once we’ve done this (with this particular matrix) we should see something like this:

Doesn’t look like a brilliant result be we only started with a tiny matrix. In this case we have all three nodes belonging to one cluster. The first node (the first row) is the ‘attractor’ – as it has values in its row it is attracting itself and the second and third row (the columns). If we were to end up with the following result (from a given initial matrix):

This basically says that we have three clusters {1,3} (with 1 as the attractor), {2,4} (with 2 as the attractor) and {5} on its lonesome.
Instead of letting you piece all that together here’s the code for Markov Clustering in Python:
import numpy as np
import math
## How far you'd like your random-walkers to go (bigger number -> more walking)
EXPANSION_POWER = 2
## How tightly clustered you'd like your final picture to be (bigger number -> more clusters)
INFLATION_POWER = 2
## If you can manage 100 iterations then do so - otherwise, check you've hit a stable end-point.
ITERATION_COUNT = 100
def normalize(matrix):
return matrix/np.sum(matrix, axis=0)
def expand(matrix, power)
return np.linalg.matrix_power(matrix, power)
def inflate(matrix, power):
for entry in np.nditer(transition_matrix, op_flags=['readwrite']):
entry[...] = math.pow(entry, power)
return matrix
def run(matrix):
np.fill_diagonal(matrix, 1)
matrix = normalize(matrix)
for _ in range(ITERATION_COUNT):
matrix = normalize(inflate(expand(matrix, EXPANSION_POWER), INFLATION_POWER))
return matrix
If you were in the mood to improve it you could write something that’d check for convergence for you and terminate once you’d achieved a stable solution. You could also write a function to perform the cluster interpretation for you.
As you were.
what is the use of self loop.
As I understand it, it’s about adding 1 on the diagonal of the matrix, to avoid mistakes, especially when dealing with bigger arrays. The whole thing is explained here:
https://www.cs.ucsb.edu/~xyan/classes/CS595D-2009winter/MCL_Presentation2.pdf
Great article, thanks a lot, it made me understand the point of MCL.
why I got this error : def expand(matrix, power)
^
SyntaxError: invalid syntax
You are missing a colon
hi
I have a proposal for a master’s thesis about protein_protein intraction prediction by markov clustering .
can you help me
i dont know how write it